LRU和LinkedHashMap
本文主要记录LRU算法和其实现方式LinkedHashMap的源码解析。
LRU算法
LRU全称为最近最少使用算法,一般用在缓存中,所以他一般会有个固定的容量,当数据不满时可以一直往里插入数据,当数据满了后再插入数据时会把最先插入的那条数据给移除掉,再把要插入的数据放在最新的位置。举个例子:
假设现在LRU缓存容量为4,我们有[1,2,3,4,5,2,5,6] 这几个数据要保存在LRU缓存中,插入过程如下图所示:
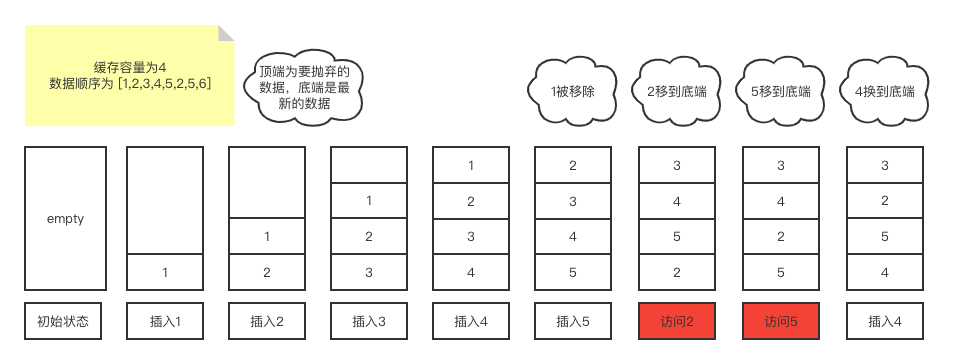
当缓存满了时,LRU在插入新数据时会把最老的那条数据给移除掉,并且把当前数据插入到最新的位置,当访问老数据时会把老数据放到最新的位置,从而保证老数据不那么轻易被移除掉。
知道LRU的特性后,那么问题来了,如何实现这样一个数据结构呢?Java其实给我们提供了一个叫做LinkedHashMap的数据结构,它完美满足了LRU的这些特性。
LinkedHashMap
用法
val map = LinkedHashMap<String,Int>()
map.put("黄二狗",28)
map.put("李大爷",56)
val ageOfErGou = map.get("黄二狗")
val ageOfLiDaYe = map.get("李大爷")
可以看出LinkedHashMap和HashMap的用法看上去是差不多的,接下来可以探究下LinkedHashMap的源码。
源码解析
类和构造函数
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>{
/**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail;
public LinkedHashMap() {
super();
accessOrder = false;
}
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
//此处重写了HashMap中的newNode方法,newNode方法会在put方法里被调用
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
// link at the end of list
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
}
可以看出LinkedHashMap继承自HashMap,所以它具有HashMap的基本特性,他的Entry类也是继承自HashMap的Node类,并且添加了before、after两个节点,所以它的Entry其实是个双向链表。LinkedHashMap内部结构大致如下所示:
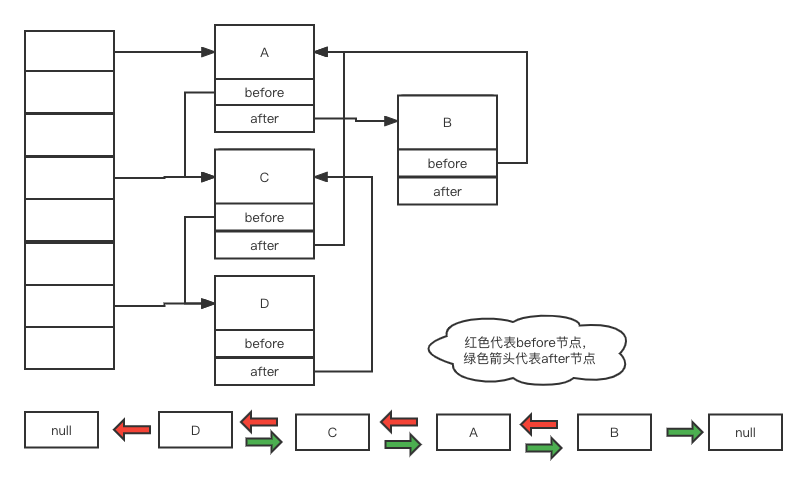
根据HashMap的特性我们可以知道,在没有hash冲突的情况下HashMap查找效率为O(1),所以LinkedHashMap在插入数据时可以迅速找到要在数组中插入的位置,随后通过往双向链表的末尾添加一个Entry实现新数据永远在双向链表的末尾,老数据永远在双向链表的头部,当新老数据交换时只需要操作头尾指针即可(有可能要先通过HashMap查找),由于链表的插入和删除都是O(1)复杂度,所以保证了LinkedHashMap的操作基本都是O(1)的时间复杂度。
LinkedHashMap完美解决了LRU缓存的实现问题,但是如果叫我们自己去实现一个时间复杂度为O(1)的LRUCache那么该怎么去实现呢?
自己实现一个LRUCache
这是LeetCode上的一道算法设计题LeetCode题目146LRUCache,具体实现代码如下:
class LRUCache(capacity: Int) {
private val mCap = capacity//容量
private val map: HashMap<Int, Entry> = HashMap(capacity)//方便O(1)查找
//辅助节点很重要,不然要写一大堆if逻辑,容易出错
private var head: Entry = Entry(-1, -1)//辅助头节点,不会变化,head永远指向此对象
private var tail: Entry = Entry(-1, -1)//辅助尾节点,tail永远指向此对象,辅助节点
init {
head.next = tail
tail.prev = head
}
//删除真正意义上的头节点
fun deleteRealHead(entry: Entry) {
head.next = entry.next
entry.next?.prev = head
entry.prev = null
entry.next = null
}
//删除当前节点
fun deleteEntry(entry: Entry){
entry.prev?.next = entry.next
entry.next?.prev = entry.prev
entry.next = null
entry.prev = null
}
//把当前节点添加到末尾
fun add2tail(entry: Entry){
entry.next = tail
entry.prev = tail.prev
tail.prev?.next = entry
tail.prev = entry
}
fun get(key: Int): Int {
val entry = map.get(key)
if (entry == null) {
return -1
}
deleteEntry(entry)
add2tail(entry)
return entry.value
}
fun put(key: Int, value: Int) {
val entry = map.get(key)
val size = getSize()
if (entry == null) {
val newEntry = Entry(key,value)
map.put(key,newEntry)
add2tail(newEntry)
if(size >= mCap){
//满了
map.remove(head.next?.key!!)
deleteRealHead(head.next!!)
}
}else{
entry.value = value
deleteEntry(entry)
add2tail(entry)
}
}
fun getSize(): Int {
return map.size
}
// 封装的数据结构(双向链表),包含key、value和左右两个兄弟节点
inner class Entry(val key: Int, var value: Int, var prev: Entry? = null, var next: Entry? = null)
}
核心步骤如下:
- 定义Entry类(双向链表),包含key、value和左右兄弟节点
- 定义两个辅助节点head和tail(key和value随便取),在整个数据操作过程中head和tail指向不会改变。
- 定义一个Map存储key和Entry对
- 当get时需要把get的数据移动到末尾(前提已经存在这条数据)
- 当put时需要根据情况进行操作,具体看代码
Java异常Throwable总结
本文记录个人关于Java异常机制的理解和总结。
首先先看Java关于异常的类结构图
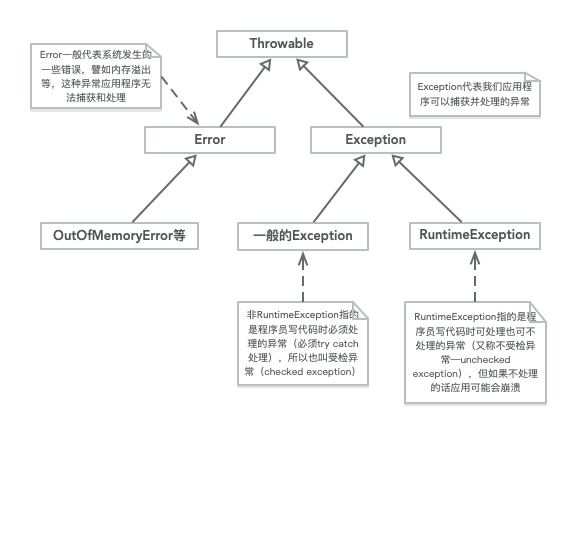
Java的异常都继承自Throwable,异常分两个大类Exception和Error
- Exception代表普通的异常,譬如常见的NullPointerException、ArrayIndexOutOfBoundsException等,Exception使用
try{}catch}{}finally{}语句块进行处理- Exception又分运行时异常和非运行时异常。运行时异常是指写代码时可处理也可不处理的那种异常,写代码时不会报错,但是运行时就会崩溃;非运行时异常指的是那些编码过程中如果不使用trycatch捕获ide就会报错的那种异常,譬如IOException。
- 非运行时异常又称为受检异常(checked exception)
- Error代表错误,一般是由系统抛出的,譬如StackOverFlowError、OutOfMemoryError,Error一般不建议捕获,因为一般来说程序发生了Error系统就无法继续往下运行(但某些情况下实际上也可以通过trycatch机制捕获)
用法
fun tryCatch():Int{
var i = 0
try{
i++
//这里如果发生异常或抛出异常整个结果为3
throw NullPointerException("asdas")
return i
}catch (e:NullPointerException){
i++
return i
}finally {
//finally语句一定会执行,并且优先于return执行(就算天皇老子来了也会执行)
i++
return i // 去除这句会导致返回值少1,加上后try和catch中的return语句都失效
}
}
- 如果不去掉finally中的return语句那么这个函数返回2,执行try和fnally的i++,最后finally中的return语句执行
- 如果去掉finally中的return那么这个函数返回1,首先执行try语句的i++,然后缓存try语句里i的值作为返回值,最后finally的i++也会执行,但是finally语句的结果不作为返回值返回。对于基本类型是这样处理的,但是引用类型就不一样了,finally的改动也会映射到对象上,finally如果有return语句会导致try和catch中的return无效。
- 如果try语句里i++后发生了异常,那么这里返回值为3
异常原理
JVM使用异常表来处理异常的逻辑,异常表里分别会记录try、catch和finally三个语句块的指令的开始和结束位置,然后如果发生异常的话就跳到指定位置进行执行,这里具体可以看一下深入理解Java虚拟机那本书里虚拟机执行子系统这章看看。
startActivity原理
本文主要从源码角度解析Android中调用startActivity方法启动新页面时的原理。
先贴下源码关键类路径:
/core/java/android/app/ContextImpl.java
/core/java/android/app/Instrumentation.java
/core/java/android/app/ActivityThread.java
/core/java/android/app/ActivityTaskManager.java
/core/java/android/app/IActivityTaskManager.aidl
使用方法
在安卓中要启动一个新页面时一般采用下面的方法:
context.startActivity(new Intent(context,XXXActivity.class));//XXXActivity是新页面的类名
这里的context一般是Activity也可以是Application、Service,但是如果在targetSdkVersion大于或者等于9.0或者targetSdkVersion小于7.0并且context不是Activity的话需要使用Intent.addFlags(Intent.FLAG_ACTIVITY_NEW_TASK)或者Intent.setFlags(Intent.FLAG_ACTIVITY_NEW_TASK)设置flag,不然系统会抛出一个运行时异常如下:
Calling startActivity() from outside of an Activity context requires the FLAG_ACTIVITY_NEW_TASK flag. Is this really what you want?
这个异常的意思是在非Activity类型的Context中调用startActivity方法必须设置Intent.FLAG_ACTIVITY_NEW_TASKflag,而Activity不用加这个flag的原因是因为Activity重写了startActivity方法,而其他的组件使用的都是ContextImpl里的startActivity方法(其他组件都间接或者直接继承了ContextImpl),下面先来看看ContextImpl中的startActivity方法的调用
源码分析
本章主要根据源码分析startActivity调用过程
ContextImpl启动Activity
源码如下:
public void startActivity(Intent intent, Bundle options) {
warnIfCallingFromSystemProcess();
// Calling start activity from outside an activity without FLAG_ACTIVITY_NEW_TASK is
// generally not allowed, except if the caller specifies the task id the activity should
// be launched in. A bug was existed between N and O-MR1 which allowed this to work. We
// maintain this for backwards compatibility.
final int targetSdkVersion = getApplicationInfo().targetSdkVersion;
if ((intent.getFlags() & Intent.FLAG_ACTIVITY_NEW_TASK) == 0
&& (targetSdkVersion < Build.VERSION_CODES.N
|| targetSdkVersion >= Build.VERSION_CODES.P)
&& (options == null
|| ActivityOptions.fromBundle(options).getLaunchTaskId() == -1)) {
throw new AndroidRuntimeException(
"Calling startActivity() from outside of an Activity "
+ " context requires the FLAG_ACTIVITY_NEW_TASK flag."
+ " Is this really what you want?");
}
//mMainThread是ActivityThread的实例,getInstrumentation得到的是Instrumentation的实例
mMainThread.getInstrumentation().execStartActivity(
getOuterContext(), mMainThread.getApplicationThread(), null,
(Activity) null, intent, -1, options);
}
由源码可知ContextImpl中的startActivity方法最后调用的是Instrumentation类的execStartActivity方法,再继续看看Activity中的startActivity方法是怎么实现的。
Activity启动Activity
Activity中经过一系列调用后都会走到startActivityForResult(@RequiresPermission Intent intent, int requestCode,@Nullable Bundle options) 方法中,此方法的源码如下:
public void startActivityForResult(@RequiresPermission Intent intent, int requestCode,
@Nullable Bundle options) {
//mParent也是Activity的实例
if (mParent == null) {
//......省略无关代码
//调用的还是Instrumentation的execStartActivity方法
Instrumentation.ActivityResult ar =
mInstrumentation.execStartActivity(
this, mMainThread.getApplicationThread(), mToken, this,
intent, requestCode, options);
//......省略无关代码
} else {
//startActivityFromChild方法最后也会调用到当前方法中
if (options != null) {
mParent.startActivityFromChild(this, intent, requestCode, options);
} else {
// Note we want to go through this method for compatibility with
// existing applications that may have overridden it.
mParent.startActivityFromChild(this, intent, requestCode);
}
}
}
由源码得出Activity中也是调用的Instrumentation中的execStartActivity方法,所以所有的startActivity方法调用底层都是通过Instrumentation类中的execStartActivity实现的,下面再来看看execStartActivity方法
Instrumentation.execStartActivity方法解析
public ActivityResult execStartActivity(
Context who, IBinder contextThread, IBinder token, Activity target,
Intent intent, int requestCode, Bundle options) {
IApplicationThread whoThread = (IApplicationThread) contextThread;
//......省略
try {
intent.migrateExtraStreamToClipData();
intent.prepareToLeaveProcess(who);
int result = ActivityTaskManager.getService()
.startActivity(whoThread, who.getBasePackageName(), intent,
intent.resolveTypeIfNeeded(who.getContentResolver()),
token, target != null ? target.mEmbeddedID : null,
requestCode, 0, null, options);
checkStartActivityResult(result, intent);
} catch (RemoteException e) {
throw new RuntimeException("Failure from system", e);
}
return null;
}
execStartActivity最后调用的是ActivityTaskManager.getService().startActivity,继续查看
ActivityTaskManager中的实现。
ActivityTaskManager
public class ActivityTaskManager{
......
/*
* 通过单例模式获取实例
*/
public static IActivityTaskManager getService() {
return IActivityTaskManagerSingleton.get();
}
@UnsupportedAppUsage(trackingBug = 129726065)
private static final Singleton<IActivityTaskManager> IActivityTaskManagerSingleton =
new Singleton<IActivityTaskManager>() {
@Override
protected IActivityTaskManager create() {
final IBinder b = ServiceManager.getService(Context.ACTIVITY_TASK_SERVICE);
return IActivityTaskManager.Stub.asInterface(b);
}
};
.......
}
IActivityTaskManager是一个AIDL文件,这里通过IPC调用到了system_server进程中,system_server进程中的ActivityTaskManagerService类对startActivity请求做处理[^问题1],下面来看看ActivityTaskManagerService是怎么处理的。
ActivityTaskManagerService
Java中的equals、==和hashCode
面试时总会被问到equals和==有什么区别,今天来总结下。
前言
首先先定义Person类,下面都会以Person类举例
//未重写equals版本
public class Person{}
//重写equals版本
public class Person{
private String name;
public Person(String name){
this.name = name;
}
public String getName(){
return name;
}
public boolean equals(Object obj){
if(this == obj){
return true;
}
if(!(obj instanceof Person)){
return false;
}
return Objects.equals(name,obj.getName());
}
}
==相关
双等号在Java中用来判断两个数据是否相等或者两个对象是否是同一个对象。
用法
比较基本类型
int a = 1;
int b = 2;
int c = 1;
System.out.println(a == b);//输出false
System.out.println(a == c);//输出true
比较引用类型(譬如Person类)
Person p1 = new Person();
Person p2 = new Person();
Person p3 = p1;
System.out.println(p1 == p2);//输出false
System.out.println(p1 == p3);//输出true
总结
对于基本类型来说,==比较的是他们的值是否一样,而对于引用类型来说,==比较的是引用类型指向的对象是否是同一个对象。
equals相关
首先看看Object类里的equals方法
public class Object{
...
public boolean equals(Object obj) {
return (this == obj);
}
}
所以对于Object类来说,equals和==其实是没有区别的,判断的都是两个引用是否指向同一个对象,对于没有重写equals方法的类来说它两也是没有区别的,但是对于重写了equals方法的类来说那就有区别了,equals方法此时走的是我们重写的逻辑,以上面重写了equals方法的Person类来举个例子:
Person p1 = new Person("小强");
Person p2 = new Person("小强");
Person p3 = new Person("光头强");
System.out.println(p1 == p2);//输出false
System.out.println(p1.equals(p2));//输出true
System.out.println(p1 == p3);//输出false
System.out.println(p1.equals(p3));//输出false
从输出结果可以看出,对于不指向同一个对象的引用用==比较后肯定返回false,而用equals比较返回的值走的是equals方法里的逻辑。
equals的特性:
- 对于不是null的两个对象A和B,如果A.equals(B)返回true那么B.equals(A)也必须返回true
- 对于不是null的对象A,A.equals(A)必须返回true
- 对于不是null的三个对象A、B和C,如果A.equals(B)返回true并且B.equals(C)返回true那么A.equals(C)也必须返回true
- 对于没有修改过的不是null的两个对象A和B,A.equals(B)一定返回相同的结果
- 对于不是null的对象A,A.equals(null)必须返回false
基本类型的equals
对于基本类型的equals方法要找基本类型对应的包装类
Byte
public boolean equals(Object obj) {
if (obj instanceof Byte) {
return value == ((Byte)obj).byteValue();
}
return false;
}
Integer
public boolean equals(Object obj) {
if (obj instanceof Integer) {
return value == ((Integer)obj).intValue();
}
return false;
}
Float
public boolean equals(Object obj) {
return (obj instanceof Float)
&& (floatToIntBits(((Float)obj).value) == floatToIntBits(value));
}
Double
public boolean equals(Object obj) {
return (obj instanceof Double)
&& (doubleToLongBits(((Double)obj).value) ==
doubleToLongBits(value));
}
其他几个就不一一列举了,基本和Integer差不多,Float和Double的equals方法比较有意思,它是先把Float转化为32位的int类型再比较转化后int的值,Double则是转化为64位long类型再比较转化后long的值。
hashCode
先来看看Object底层hashCode方法是怎么实现的
public class Object{
...
/**
* Returns a hash code value for the object. This method is
* supported for the benefit of hash tables such as those provided by
* {@link java.util.HashMap}.
* <p>
*/
public native int hashCode();
}
从英文注释可以看出hashCode方法会返回对象的hash值(默认返回的是对象在堆里的地址),并且hashCode方法是为了支持Java中的哈希表(例如HashMap)而设计的。
hashCode有以下几个特性
- 同一个对象的hashCode在应用的生命周期的任何时候都一样
- 如果两个对象equals那么hashCode也必须一样
- hashCode一样的两个对象不一定equals
总结
- 对于基本类型而言,==和equals方法可以看作是没有区别的,比较的都是基本类型的值
- 对于引用类型而言,如果没有重写equals方法,==和equals是没有区别的,比较的是对象的地址,如果重写了equals方法那么走的就是equals方法的逻辑
EventBus的使用与源码解析
本文主要介绍EventBus在android下的使用和对关键源码的解析。
介绍以及用法
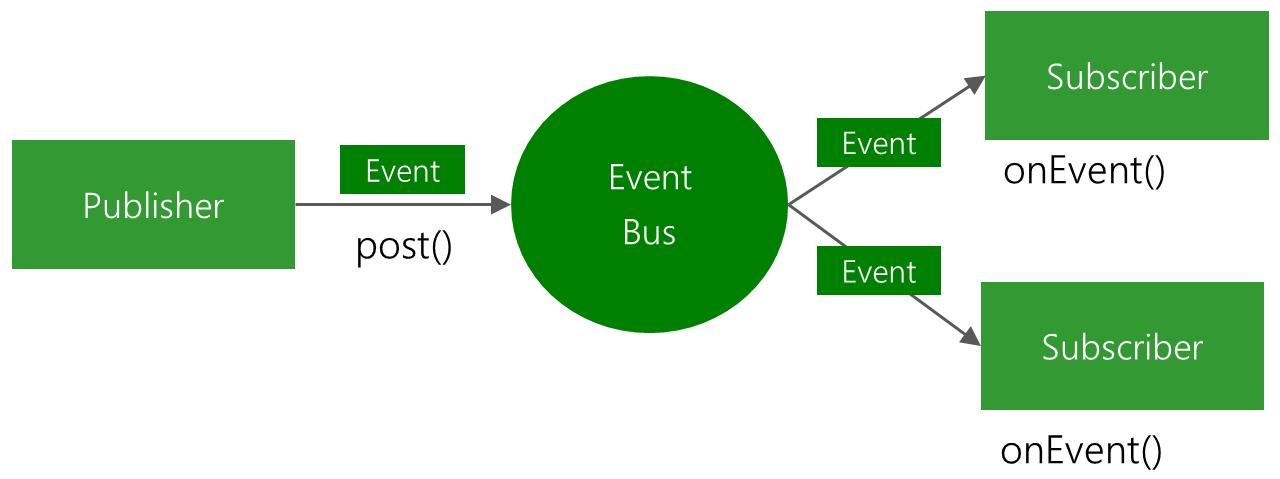
根据官网的描述我们可以知道EventBus是一个实现了发布/订阅1模式的库,并且这个库是在Android和Java中使用的,整个流程如下:
使用EventBus的好处有主要有以下几点:
- 简化了组件的通信
- 简化代码
- 快速
- jar包小
- ……
下面先来看看EventBus的使用方法:
步骤一:定义一个Event类(直接用包装类也行,但一般会定义一个Event类,直接用基本类型是不行的2)
public class Event {
}
步骤二:在订阅者类中使用@Subscribe注解观察Event的方法,在合适的地方注册订阅者并且在合适的地方取消注册,以Android中的Activity为例(随便一个类都行):
public class Activity extends AppCompatActivity{
@Override
public void onCreate(Bundle savedInstanceState){
super.onCreate(savedInstanceState);
EventBus.getDefault().register(this);//注册订阅者
}
/*
* 必须只有一个参数,并且方法访问权限必须是public的,返回值必须是void
*/
@Subscribe
public void onEvent(Event event){
//后续逻辑
}
@Override
public void onDestroy(){
super.onDestroy();
EventBus.getDefault().unregister(this);//取消当前Activity的订阅,不取消会内存泄漏
}
}
步骤三:在合适的地方发送Event
EventBus.getDefault().post(new Event());//步骤二中的onEvent方法将会被调用
我在看完源码后对EventBus的总体理解是:EventBus就是一辆车,车上的司机会发送一些通知,当你没上车时,你是收不到这些通知的,当你上车了之后(register后),你就可以收到想要的(@Subscribe注解过的)通知,当你下车了之后(unregister后)你就再也收不到车上发的通知了。
源码解析
从上面的用法以及介绍可以知道EventBus有三个重要的方法register、post、unregister,我们先从几个重要的概念和构造函数开始,然后一一讲解一下这三个方法的实现原理,首先先看看ThreadMode和@Subscribe注解。
ThreadMode
ThreadMode用在@Subscribe中,代表订阅者收到注册的事件后的onEvent方法将运行在哪个线程上,默认的情况是事件在哪个线程发送就在哪个线程运行
public enum ThreadMode{
//在哪个线程post的的就在哪个线程运行
POSTING,
//如果当前运行环境是Android,则运行在主线程,并且onEvent方法运行时会阻塞主线程;如果运行环境是Java则和POSTING一样
MAIN,
//运行在主线程,并且按顺序运行
MAIN_ORDERED,
//如果当前post时是主线程则运行在后台线程,否则的话运行在当前线程上
BACKGROUND,
//总是运行在异步线程
ASYNC
}
@Subscribe注解
@Subscribe注解用在订阅者类中需要收到Event的方法上,有了@Subscribe注解的方法代表这个方法可以收到EventBus发过来的事件,@Subscribe源码如下:
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.METHOD})//只用于方法上
public @interface Subscribe{
//代表注解的方法运行在哪个线程,默认是那个线程发送的事件那么就在哪个线程运行
ThreadMode threadMode() default ThreadMode.POSTING;
//是否是粘滞事件,默认不是
boolean sticky() default false;
//事件优先级
int priority() default 0;
}
SubscriberMethod
SubscriberMethod用于封装@Subscribe的方法,当使用register方法时会把订阅者类中所有@Subscribe注解的方法都封装成SubscriberMethod对象,并且把SubscriberMethod对象和订阅者对象一起存入Subscription中:
public class SubscriberMethod{
final Method method;//通过反射获取的方法
final Class<?> eventType;//事件类型
final ThreadMode threadMode;
final boolean sticky;
final int priority;
}
Subscription
Subscription用于封装订阅信息,内部持有订阅者对象和订阅方法对象的实例,方便post后通过反射调用方法
public class Subscription{
final Object subscriber;//订阅者对象
final SubscriberMethod subscriberMethod;//订阅方法对象
}
构造函数
public class EventBus{
//单例对象
static volatile EventBus defaultInstance;
//默认建造者
private static final EventBusBuilder DEFAULT_BUILDER = new EventBusBuilder();
//存储Event的类和注册此类型的订阅信息列表的map对象
private final Map<Class<?>,CopyOnWriteArrayList<Subscription>> subscriptionsByEventType;
//存储订阅者和订阅者注册的所有event的class的map对象,用于取消订阅
private final Map<Object,List<Class<?>>> typesBySubscriber;
//粘滞事件(一注册就会收到的那种)
private final Map<Class<?>,Object> stickyEvents;
public static EventBus getDefault(){
if(defaultInstance == null){
synchronized(EventBus.class){
if(defaultInstance == null){
defaultInstance = new EventBus();
}
}
}
return defaultInstance;
}
public EventBus(){
this(DEFAULT_BUILDER);
}
}
从构造函数可以看出EventBus使用了建造者模式和伪单例模式(构造函数是public的)进行初始化,这里可以把EventBus看作一辆车,如果你想上默认的车就必须使用getDefault方法提供的EventBus实例,如果不想的话就可以使用EventBusBuilder自己构造一个EventBus然后上车。
register方法
post方法
unregister方法
-
反射不支持自动装箱机制(自动装箱是在编译期间的,而反射在运行期间) ↩
Java字符串String详解
这是一个模板文件
HashMap源码解析
本文主要记录Java中集合类HashMap的使用以及从源码(基于Java 8)的角度分析它的实现原理。
HashMap介绍
HashMap是一种通过键值对映射(key-value)的方式存储数据的一种集合对象,每个key最多只能对应一个value,HashMap的用法一般如下所示:
HashMap<String,String> map = new HashMap<>();//初始化HashMap
map.put("a","hahaha");//把“a”处映射的value设为“hahaha”
String value = map.get("a");//取出key为“a”的数据,此时value就是上面的“hahaha”
HashMap这个单词可以分两部分看,第一部分是Hash、然后是Map。在Java中Hash代表的就是hashCode,阅读过Object源码的都知道Object类中有hashCode和equals方法,设计这两个方法的目的也就是为了方便Java中哈希表集合类的使用,而Map在Java中则代表Map接口,Map接口在Java中被定义为是一个提供key和value之间映射的对象,并且同一个map中不能包含多个相同的key,每个key最多只能映射一个value,这有点类似于数据库里的主键和数据之间的映射关系,HashMap的大致结构如下图所示:
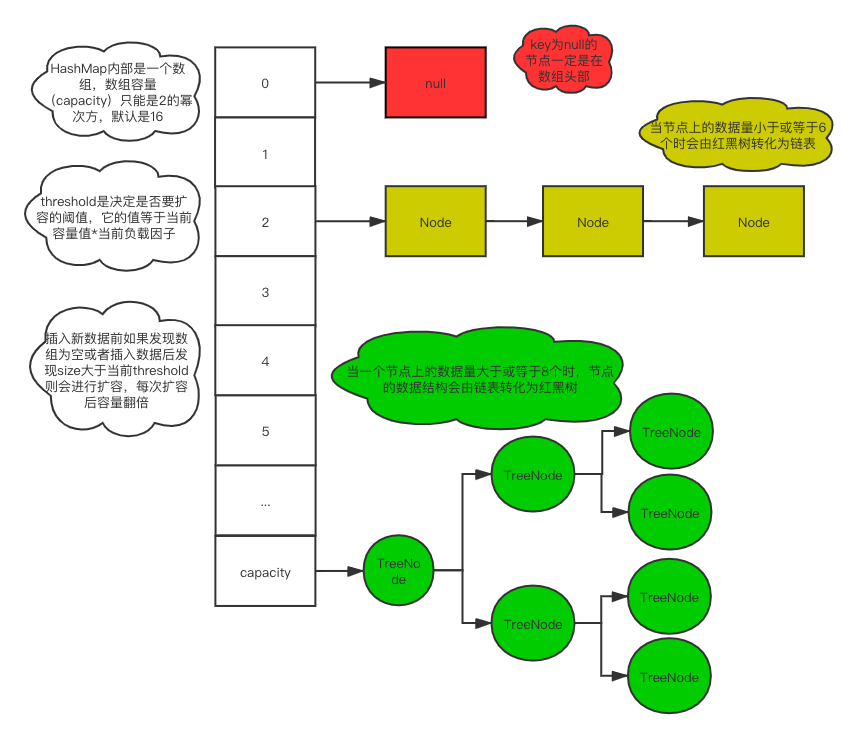
HashMap源码解析
从上面的图我们可以知道HashMap底层使用数组+链表+红黑树三巨头实现的,先来看看源码中HashMap类的定义和它重要的几个属性:
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;//默认的初始容量为16
static final float DEFAULT_LOAD_FACTOR = 0.75f;//默认负载因子为0.75
static final int TREEIFY_THRESHOLD = 8;//链表转化为红黑树的容量阈值
static final int UNTREEIFY_THRESHOLD = 6;//红黑树转化为链表的容量阈值
//节点数组,用于保存所有的数据,数组的实际容量只能是2的幂次方,每次扩容增长为原来的两倍
transient Node<K,V> [] table;
final float loadFactor;//负载因子
int threshold;//数组扩容的数据量阈值,值等于capacity*loadFactor
int size;//数据量大小,注意这个不是table的长度,每put一个数据size要加1
...
}
首先可以看出HashMap有两个泛型K和V,其中K代表键、V代表值,并且HashMap继承了AbstractMap、实现了Map接口(这里有点疑惑为什么HashMap要重新实现Map接口,因为AbstractMap已经实现了Map接口,可能是历史遗留问题)1,并且HashMap还支持克隆(浅拷贝)和序列化。HashMap中有一个Node数组(也就是三巨头中的数组),Node数组保存HashMap中的所有数据,要理解HashMap存储与取值过程首先要理解HashMap中的静态内部类Node、TreeNode和HashMap里面的几个重要的骚操作,首先看看Node,也就是三巨头中的链表。
静态内部类Node类解析
Node类源码如下所示:
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
//...
public static class Node<K,V> implements Map.Entry<K,V>{
final K key;
V value;
final int hash;
Node<K,V> next;
//其他方法省略,就是一些很普通的针对Object类方法的重写(譬如equals和hashCode)
...
}
}
由Node源码可以看出,Node是个链表,保存了key和value,并且key和hash是final的(这保证了HashMap在get的时候不会定位到错误的位置)。
静态内部类TreeNode解析
三巨头除了数组和链表之外还有红黑树,那么这个红黑树就是我们接下来要说的TreeNode,TreeNode源码大致如下:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent;
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev;
boolean red;
//...其他则是红黑树的一些常用方法
}
从源码可以看出TreeNode继承LinkedHashMap.Entry,点进LinkedHashMap.Entry类里可以知道LinkedHashMap.Entry继承HashMap.Node,所以其实TreeNode也是Node的子类,只不过多了红黑树的一些方法,这样就可以在table数组里存储红黑树的实例了。
HashMap重要骚操作
HashMap之所以高效是因为HashMap里面用到了几个骚操作(其实最主要是位操作),桶定位、tableSizeFor(找出一个比给定值更大的2的幂次方的值)和hash方法(保证散列性,降低碰撞),下面梳理下这三个骚操作。
-
桶定位
通过前面的分析可以知道HashMap里有一个table数组,数组长度是2的幂次方,table里的每一项我们称之为一个桶,桶定位的意思就是给定一个key,通过计算key的hash值我们可以把它定位到数组里的某一个桶,那么怎么做才简单高效呢?答案就是下面第二行代码:
int size = table.length;//数组长度 int index = (size - 1) & hash;//得到的index的值一定是在0-size之间由于size一定是2的幂次方所以(size-1)的低位一定全是1、高位全是0,所以根据&运算符的特性我们可以得出最后index的值一定是落在0-size之间。
-
HashMap在当初始化时用户可以传入initialCapacity参数代表初始容量,但我们知道HashMap的容量只能是2的幂次方,所以必须要有一个方法通过initialCapacity计算一个大于或等于它的数值作为数组的容量,HashMap中的静态方法tableSizeFor就是干这件事的,tableSizeFor方法源码如下:
public static int tableSizeFor(int cap){ int n = cap - 1;//1 n |= n >>> 1;//2 n |= n >>> 2;//3 n |= n >>> 4;//4 n |= n >>> 8;//5 n |= n >>> 16;//6 return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;//7 }这段代码的作用就是生成一个比cap大的或等于的最接近的2的幂次方的数值,这段代码很精妙,但也挺好理解,下面随便考虑一个数(补码表示):
0010 1101//真值是+45如果我们想找到一个比这个数大的2的幂次方的数该怎么办呢?其实很容易可以想到只要从左到右找到第一个1存在的位置,然后左移一位,最后低位全部清0就行(当然这里不能超过int类型最大值的限制),具体过程如下:
0010 1101 0101 1010//左移一位 0100 0000//低位全部清0,此时结果是64,符合要求原理很简单,HashMap实现时采用了另一种思路,要实现低位全部清0,那么只要低位全部为1并且高位全部是0之后再加上1就行了,所以得出了上述代码,至于第一步要减去1的理由是如果传入的cap已经是2的幂次方了,不减去1得到的结果是cap*2,不符合大于或等于的最接近的2的幂次方这个要求。
-
HashMap的hash方法没有直接使用key的hashCode,而是自己有一个hash方法,所有的key都要经过这个hash方法后存储到Node中去,hash方法源码如下:
public static int hash(Object key){ int h; return key == null ? 0:(h = key.hashCode())^(h >>> 16); }这段代码的作用是输入一个key,如果key为null则返回0,如果不是则把key的高16位不变,低16位与高16位异或然后返回异或后的结果,这样做的好处是为了让高位与低位都参与到hash计算中去,降低hash碰撞的概率。降低hash碰撞的好处就是可以降低时间复杂度,HashMap最好的情况就是数组里面的桶里只有单个元素(既不是链表也不是红黑树),这样查找的时间复杂度可以降到O(1)。通过降低hash碰撞的概率,可以达到基本上每个桶上只有一个元素的状态,此时效率自然就提升了。
通过前面的分析可以大致得到HashMap的内部结构和一些重要的骚操作了,接下来就进入正题,HashMap到底是怎么存储和获取数据的呢?
resize方法
通过前面的分析我们知道HashMap中的table是有容量限制的,如果一直使用默认的容量,当数据越来越多时,hash碰撞就会越来越严重,效率也就越来越慢,那么为了解决这个问题就有必要对table进行扩容。HashMap中的扩容动作一般是在新增数据时也就是put方法调用时执行的,put数据时扩容一般有两种情况:
- put时发现table为null或者table长度为空
- put数据完成后发现HashMap的size大于threshold(也就是阈值)
扩容方法也就是resize方法伪代码如下(忽略最大值处理):
Node<K,V> resize(){
Node<K,V> newTable = table;
int oldCap = table == null ? 0 : table.size();//获取当前数组容量
int oldThr = threshold;//获取当前阈值
int newCap,newThr = 0;//定义新的容量和新的阈值
if(oldCap > 0){
newCap = oldCap << 1;//扩容为原来的两倍
newThr = newCap * loadFactor;//阈值也变为原来的两倍
}else if(oldThr > 0){
newCap = oldThr;//这种情况一般是用户初始化HashMap时自己定义了初始容量
}else{
//用户使用的是默认构造函数
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = newCap * DEFAULT_LOAD_FACTOR;
}
if(newThr == 0){
newThr = newCap * loadFactor;
}
threshold = newThr;//重新赋值阈值
//遍历整个table,做移动数据等操作,这里省略
return newTable;
}
通过上面的伪代码可以得到resize方法的执行流程如下所示:
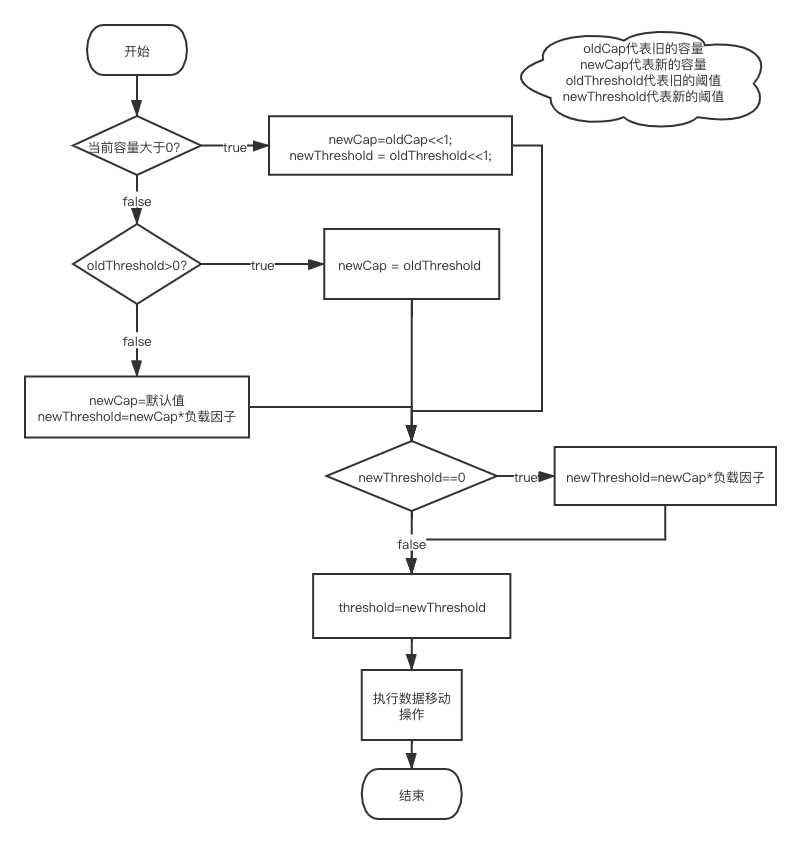
通过伪代码和流程图可以得出两个结论:
- HashMap在使用默认构造函数初始化时默认容量为16,阈值为16*0.75(默认负载因子)
- HashMap每次扩容后容量会变为原来的两倍,并且阈值也会变为原来的两倍
put方法
话不多说,先来看伪代码:
public V put(K key,V value){
int hash = hash(key);//通过内部hash方法获取key的hash值
Node<K,V> p;
if(table == null || table.length == 0){
resize();//如果当前数组是null或者数组长度为空则进行扩容
}
int index = (table.length-1) & hash;
p = table[index];//根据hash值找到Node对应的桶,并返回桶中链表的头指针或者红黑树的根节点
if(p == null){
//如果当前的桶内没有数据则直接新建一个Node放入桶内
table[index] = new Node<>(hash,key,value,null);
}else{
//当前桶内已经有数据了
Node<K,V> result;
if(hash == p.hash && key.equals(p.key)){
//如果桶内第一个元素的key和当前要找的key是一样的(hash值相等并且key的equals为true),那么说明数据已经找到,只需要把新值赋进去就行
result = p;
}else if(p instanceof TreeNode){
//当前桶内数据结构是红黑树
result = 红黑树的相关方法;
}else{
//当前桶内是一个链表,遍历这个链表找key是当前搜索key的节点,如果
int count = 0;
for(int i=0;;i++){
if((result = p.next) == null){
result = new Node<hash,key,value,null>;
if(i >= TREEIFY_THRESHOLD - 1){
//如果当前链表长度大于规定的阈值则把链表转化为树
treeifyBin(tab, hash);
}
break;
}
if(hash == result.hash && key.equals(result.key)){
//找到对应的数据,直接break
break;
}
p = result;
}
}
if(result != null){
//当前桶内已经有这个key对应的数据
V oldValue = result.value;
result.value = value;//赋新值
return oldValue;
}
}
//当前桶内没有这个key对应的数据并且如果数据量大于扩容的阈值则进行一次扩容
if(++size > threshold){
resize();
}
return null;
}
流程图大致如下:
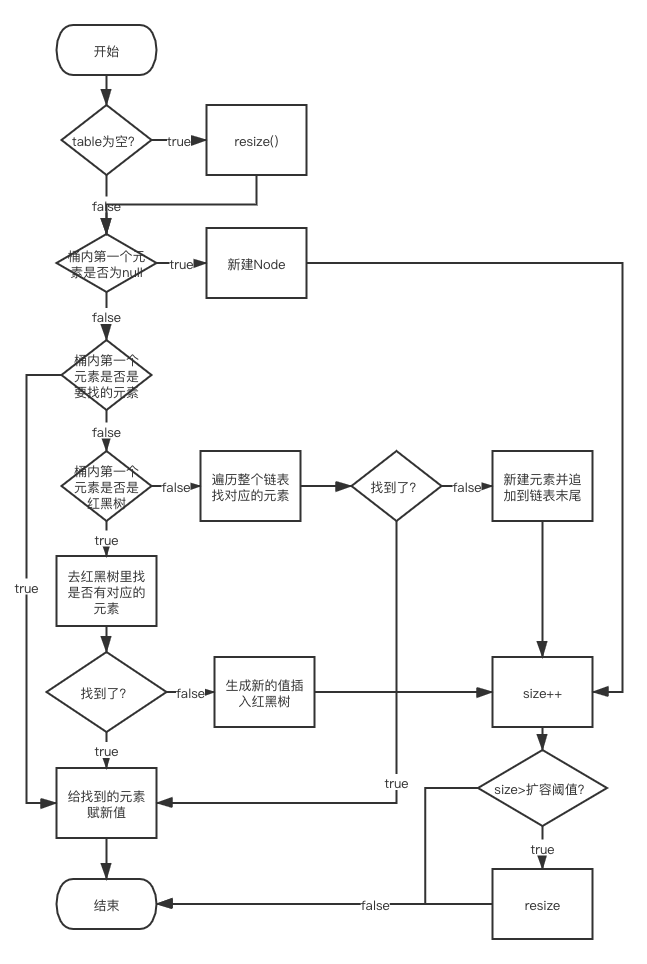
put方法的整个流程如上所述,没什么复杂的东西,最复杂的应该就是红黑树的一些操作,但put方法需要注意的点有几个:
- Java 8开始是采用尾插法插入数据到链表中的,Java 8之前都是头插法。
- put时如果是新建的Node(当前的key在HashMap中找不到对应的值)那么会判断当前table里所有数据是否大于扩容的阈值,如果大于就会进行一次扩容。
- 如果插入时对应的桶里的数据量大于规定的链表转红黑树的阈值则会把桶里的结构由链表转为红黑树。
- put方法返回的是旧的值,而不是新的值
get方法
其实知道了put方法的原理那么get方法就很简单了,猜都能猜出来是怎么做的,get方法的伪代码如下:
public V get(K key){
int hash = hash(key);
int index = (table.length - 1) & hash;//找桶的位置
Node<K,V> bucket = table[index];
if(bucket == null){
//没找到数据,返回null
return null;
}else{
if(bucket.hash == hash && key.equals(bucket.key)){
//桶内第一个元素就是要找的数据
return bucket.value;
}else if(bucket instanceof TreeNode){
//桶内的数据结构是红黑树
...用红黑树的查找方法查找数据并返回值
}else{
//桶内数据结构是链表
...用链表的查找方法查找数据并返回值
}
}
}
总结
其实也没啥好总结的,所有注意的点都写在上面了,看源码还是得要多想多看,实在想不通可以翻翻别人写的博客,但也不能一切以别人博客上说的为准,实践出真知,切记不可焦躁。
Mac电脑常用快捷键和设置
这篇文章主要记录下Mac电脑下常用的一些快捷键和设置的方法
-
Option+Command+拖动文件夹或者应用程序图标 -
1、找到android sdk安装目录(一般是/Users/用户名/Library/Android/sdk) 2、进入tools文件夹 3、emulator -list-avds //列出所有模拟器 4、emulator -avd 想要启动的模拟器名称 -
在.zshrc文件最末尾加上source ~/.bash_profile命令 -
keytool -list -v -keystore 签名文件路径
Git常见问题及解决方案
pull
问题描述:在新项目的本地执行git pull命令时,出现fatal: refusing to merge unrelated histories错误。
出现原因:因为本地库和远端库是两个根本不相干的 git 库,然后本地要去推送到远端, 远端觉得这个本地库跟自己不相干, 所以告知无法合并
解决方案:
git pull origin master --allow-unrelated-histories
Jekyll常见问题及解决方案
启动错误
问题描述:在博客项目根目录执行bundle exec jekyll serve命令时,出现Could not find nokogiri-1.10.9-x64-mingw32 in any of the sources (Bundler::GemNotFound)错误。
出现原因:因为没有安装或更新nokogiri库
解决方案:
博客项目根目录执行bundle install命令
参考文章:Could not find nokogiri-1.7.0.1 in any of the sources
问题描述:在博客项目根目录执行bundle exec jekyll serve命令时,出现Error: Permission denied - bind(2) for 127.0.0.1:4000错误。
出现原因:有其他程序占用了4000端口
解决方案:
找到占用4000端口的应用并杀死此应用进程,重新启动jekyll
文章分类
最近文章
- Java代理模式与动态代理原理 本文介绍代理模式的应用和Java中动态代理的原理
- Kotlin中suspend和async源码解读 本文主要记录Kotlin中suspend关键字和async函数的使用及源码解读
- Kotlin中线程池处理过程 本文主要记录Kotlin中线程池的调度过程
- Kotlin中异常的处理和传播 本文主要记录Kotlin中suspend关键字和async函数的使用及源码解读
- 整数转字符串 本文记录2022年四月份字节跳动三面的算法题目。